Apuntes de lenguaje ensamblador (Assembly)


Aviso legal
Realizar ingeniería inversa a determinado software suele estar restringido y prohibido en los términos y condiciones de dicho software, y bajo ciertas circunstancias puede incluso ser ilegal, dependiendo de los desarrolladores y distribuidores. Quedas avisado.
Dificultad: Difícil
Sistema Operativo: Debian 13
Herramientas requeridas:
- gdb
Conocimiento requerido:
- Conocimientos básicos de programación (entender, al menos, un simple trozo de código).
- Conocimientos de nivel promedio de hardware (conocer los componentes de un ordenador como la CPU, la RAM y demás, aparte de entender para qué sirven).
- Conocimiento básico de operaciones lógicas (saber qué son las operaciones AND, OR, XOR...)
Nota: Estos apuntes pueden llegar a variar en un futuro debido a que iré actualizando este post conforme obtenga más información .
Bienvenidos, queridos hackers, a mis apuntes. Hoy veremos cómo interpretar código ensamblador con el objetivo final de poder entender un programa, las instrucciones que ejecuta y también las acciones que realiza. Vamos a tratar algunas herramientas clásicas para asegurarnos de entender el núcleo de la ingeniería inversa, y quizá en el futuro aborde herramientas más potentes como Binary Ninja, x64dbg o Radare2 (herramientas realmente interesantes y potentes, pero no las voy a tratar en esta publicación).
Qué es "Ensamblador"?
El ensamblador (ASM) es un lenguaje de programación de bajo nivel que se sitúa entre el código de alto nivel (C, C++, Java...) y el código máquina (binario) y que ayuda a comunicarse directamente con el hardware del ordenador. Hoy en día no tiene propósito como lenguaje de programación porque (como verás) hace que el programador quiera arrancarse los ojos. Trabajar con lenguajes de alto nivel como C/C++ ya hace que el programa sea realmente eficiente, y aunque Assembly es incluso mucho más rápido que cualquier otro lenguaje de alto nivel, la abstracción que requiere para hacer un programa sencillo lo hace inviable.
Hoy en día, el ensamblador se utiliza en compiladores para crear código ensamblador a partir de programas de alto nivel, que luego se traduce a código máquina, pero también se emplea en dispositivos que requieren máxima eficiencia o un alto nivel de control sobre el hardware (como algunos Arduinos y dispositivos ESP32). Sin embargo, también es útil en ingeniería inversa, donde los binarios compilados se convierten en código máquina y, dado que el código máquina puede convertirse en instrucciones de CPU, algunos programas están diseñados para convertir esas instrucciones de CPU en código ensamblador para que las leamos. Eso hace que tengamos más probabilidades de entender el código original leyendo el código de bajo nivel y, por tanto, ahora hay programas con código oculto disponibles para nosotros.
Esto es útil cuando hacemos ingeniería inversa, ya que podríamos descubrir potencialmente:
- Contraseñas ocultas dentro del código
- Vulnerabilidades potenciales como "desbordamientos de búfer" (Buffer Overflow)
- Actividad maliciosa que podría dañarnos a nosotros o a nuestro sistema (Malware)
Así que la ingeniería inversa es realmente útil. De hecho, pude hackear el programa de mi profesor diseñado para hacer exámenes sin hacer trampas haciendo Ingeniería Inversa, ya que descubrí dentro del código una combinación de teclas del teclado que me permitía saltarme las restricciones de seguridad y, por tanto, saltarme las restricciones de seguridad de su programa. Si te lo preguntas, no, no he hecho ni he hecho trampa en ningún examen. Soy un hacker ético con una moral sólida, pero no alguien inofensivo.
Puedes ver cómo lo hice en el siguiente post:

Entendiendo la sintaxis de ASM y las arquitecturas
Después de haber presumido sobre lo útil que es la ingeniería inversa en ciberseguridad en general, voy a hablar un poco sobre las diferentes arquitecturas en Assembly (a partir de ahora ASM) y las distintas arquitecturas.
El ensamblador, al ser un lenguaje de bajo nivel, debe adaptarse al hardware del sistema operativo. En lenguajes de alto nivel como C, la sintaxis del código no cambia en absoluto porque se pensaba que era más avanzado y compatible que ASM, solo para facilitar la vida al programador. Sin embargo, esto no se aplica en ensamblador, porque se piensa que el ensamblador es el lenguaje que se comunica con la CPU, debe adaptarse al tipo de instrucción que ejecuta la CPU.
Arquitecturas
Cuando hablamos de Assembly, a menudo debemos especificar la arquitectura con la que trabajamos, porque hay muchas diferencias. Las dos arquitecturas de las que hablaré en este tutorial son x86 (32 bits) y x86_64 (64 bits), ya que son las más comunes hoy en día y también las que pueden ejecutarse en mi ordenador. Hay muchas otras, por ejemplo, otras dos arquitecturas famosas como ARM32 (32 bits) y ARM64 (64 bits) que funcionan en dispositivos móviles (así como en muchas otras), pero no voy a hablar de estas.
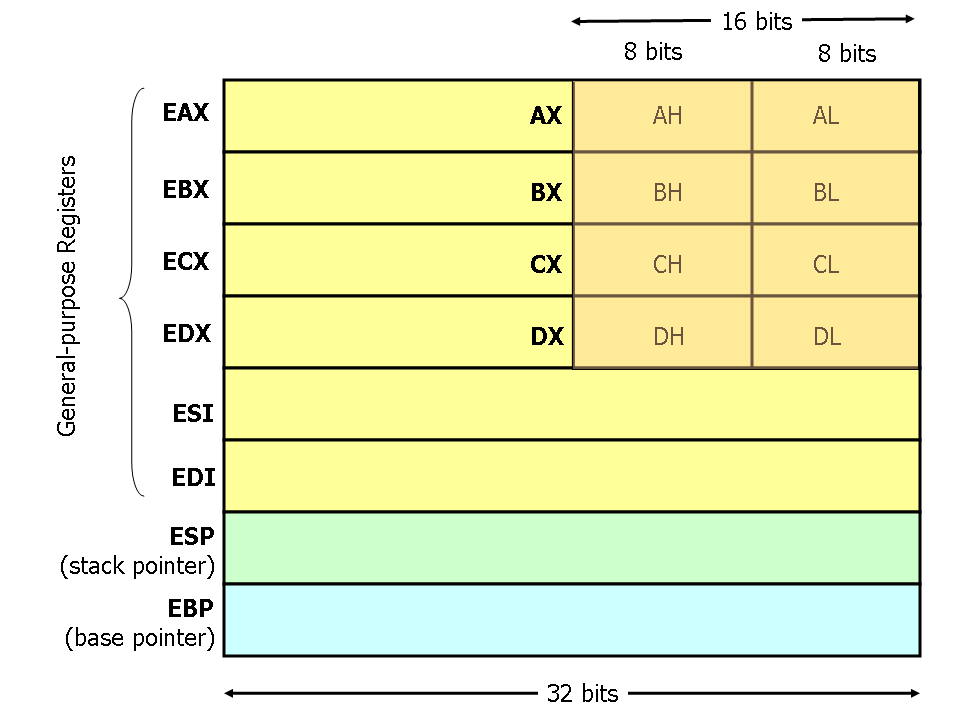
Hoy en día (a menos que tu ordenador sea demasiado antiguo) la arquitectura más común para ordenadores es x86_64. Si tu ordenador tiene más años que tu padre, entonces puede que esté usando arquitectura x86. Esta diferencia es importante porque dicta cuánta información procesa Assembly en cada operación. El lenguaje ensamblador gestiona la información usando registros, que son ubicaciones de almacenamiento pequeñas y muy rápidas construidas directamente dentro de la CPU, que almacenan datos temporalmente mientras la CPU realiza las instrucciones. Cuando hablamos de lógica de software, podemos pensar en los registros como variables que pueden contener datos en nuestro conjunto de instrucciones ensambladoras. Dependiendo de la arquitectura, los registros pueden tener algún nombre u otro. En x86 empiezan por "e" y en x86_64 comienzan con "r".
Puede que veas registros de arquitectura x86 como:
eax -> Acumulador (aritmética general)
ebx -> Registro base (propósito general)
ecx -> Contador (Usado en bucles y shifts)
edx -> Datos, para entrada/salida o multiplicaciones/divisiones
esi -> Índice de fuente (copiar cadenas de caracteres/memoria, usado junto con "edi")
edi -> Índice de destino (propósito general)
esp -> Puntero de pila (límite superior de la pila)
ebp -> Puntero base (stack frame reference)
eip -> Puntero de instrucción (Dicta qué ejecuta la CPU, muy importante para hackear)Y también puede que veas registros de arquitectura x86_64 como:
rax -> Acumulador (aritmética general)
rbx -> Registro base (propósito general)
rcx -> Contador (Usado en bucles y shifts)
rdx -> Datos, para entrada/salida o multiplicaciones/divisiones
rsi -> Índice de fuente (copiar cadenas de caracteres/memoria, usado junto con "edi")
rdi -> Índice de destino (propósito general)
rsp -> Puntero de pila (límite superior de la pila)
rbp -> Puntero base (stack frame reference)
rip -> Puntero de instrucción (Dicta qué ejecuta la CPU, muy importante para hackear)
r8 -> Propósito general (Utilizado para argumentos de funciones)
r9 -> Propósito general (Utilizado para argumentos de funciones)
r10 -> Propósito general (Registro volátil)
r11 -> Propósito general (Regitro volátil)
r12 -> Propósito general (Registro no volátil que almacena datos entre funciones)
r13 -> Propósito general (Registro no volátil que almacena datos entre funciones)
r14 -> Propósito general (Registro no volátil que almacena datos entre funciones)
r15 -> Propósito general (Registro no volátil que almacena datos entre funciones)(No te pongas nervioso/a si no entiendes nada. Hablaremos de esto más tarde. Sin embargo, siéntete libre de buscar esto en internet si estás viendo esta publicación y aún no he publicado la segunda parte. Quiero cubrir esto de forma muy detallada).
Como puedes ver, diferentes arquitecturas significan no solo distintos nombres de registros, sino también nuevas funcionalidades añadidas. Además, las diferentes arquitecturas no solo afectan la forma en que se escribe el código ensamblador, sino que también afectan a la memoria. Tener una arquitectura x86 hará que tus direcciones de memoria se vean así:
0x0040A1B8Mientras que una dirección de memoria en arquitectura x86_64 se verá así:
0x00007FF6B3C42000Las direcciones en x86_64 son más largas porque esta arquitectura está pensada para manejar mayores cantidades de datos. Esto es crucial para realizar una explotación adecuada en binarios, ya que realizar el mismo desbordamiento de búfer (por ejemplo) en una arquitectura x86 resultará en escenarios totalmente diferentes en x86_64. La dirección de memoria que se supone que debes explotar al realizar un desbordamiento de búfer es mucho más pequeña en arquitecturas x86 que en x86_64, así que el mismo exploit no funcionaría en diferentes arquitecturas. Esta es una de las razones por las que es importante distinguirlas y conocer las peculiaridades entre ellas.
Sintaxis
Las mismas arquitecturas de ensamblador pueden escribirse usando diferentes tipos de sintaxis. Mientras que en C el código siempre se escribe igual (por ejemplo, la función "printf" siempre se escribirá "printf()"), las mismas instrucciones ensambladoras pueden escribirse en diferentes tipos de sintaxis y ser válidas para la misma arquitectura e incluso para el mismo programa. Hablando de ensamblador, hay dos sintaxis principales que siguen siendo populares hoy en día.
AT&T
La sintaxis predeterminada que usan la mayoría de programas (como "gdb" u "objdump", incluso algunas herramientas más avanzadas como "binary-ninja"). Puede ser difícil de interpretar al principio, pero siendo sincero, todo código ensamblador es difícil de interpretar. En este tutorial voy a tratar esta sintaxis simplemente porque es la que más verás en vídeos de Youtube, para que tengas más lugares donde investigar más sobre este lenguaje de programación.
Una instrucción que inserte datos en un registro en ensamblador escrito con la sintaxis de AT&T sería algo así:
mov $5, %raxEsto significa que estamos copiando el valor "5" en el registro "rax". En AT&T, el símbolo "$" significa que es un valor literal constante (en este caso "5") y el símbolo "%" indica que estamos hablando de un registro (en este caso, "rax"). Hay muchas más diferencias, pero la principal es que AT&T te notifica con qué estamos interactuando en forma de símbolos, y la siguiente sintaxis de la que hablaremos no lo hace.
Intel
La sintaxis de Intel es más fácil de entender para la mayoría de los hackers debido a su simplicidad al representar la misma información que la sintaxis de AT&T. Por eso muchos hackers la prefieren sobre AT&T (yo incluído), e incluso se trata en el libro de Jon Erickson "Hacking: The Art Of Exploitation", pero como he visto la sintaxis de AT&T en la mayoría de los ejemplos de software, me ceñiré a eso.
Una instrucción que inserte datos en un registro en ensamblador escrito con la sintaxis de Intel sería algo así:
mov rax, 5Como puedes ver, en la representación de AT&T la primera palabra clave de la instrucción ("$5") es el dato que moveremos y la segunda palabra clave ("%rax") es el destino de esos datos. En la sintaxis de Intel, es lo contrario. La primera palabra clave es el destino y la segunda el valor que moveremos.
El "Stack" (La pila)
La pila es una estructura de datos que se utiliza para representar cómo la RAM almacena los datos. La estructura de pila es utilizada por todo tipo de software para almacenar datos y sigue el principio LIFO (Last In, First Out). Los últimos datos insertados dentro de la pila también serán los primeros en ser eliminados.

Para representar mejor esto, pongamos un ejemplo. La posición más cercana a 0 dentro de la pila (la tabla que he puesto en esta representación) sería la que está arriba. Imagina que tengo estas dos instrucciones ASM:
mov $42, %rax
push %raxEn este caso, los datos se insertarían (empujarían) en la parte inferior de la pila. En este caso, en la dirección "4".
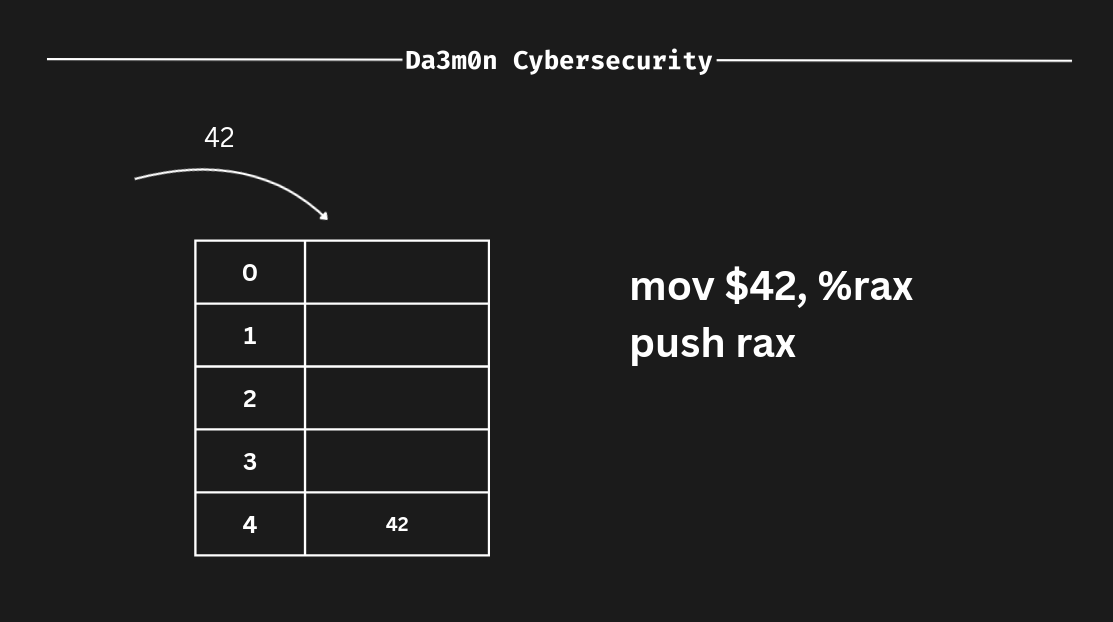
Como ASM sigue el principio LIFO, el valor que acabamos de insertar se empuja al final de la pila. Representemos otro intento para entender mejor cómo funciona la pila.

Como podemos ver, aunque he cambiado el valor que contiene "rax" "moviendo" el valor literal "13" al registro "rax", dentro de la pila los últimos datos que insertamos conservan su valor (la dirección 4 sigue conteniendo el valor "42", aunque el valor del registro haya cambiado. Esto se debe a que la pila es una representación de direcciones de memoria, y los registros son unidades de almacenamiento dentro de la CPU).
Pero, ¿qué ocurre si eliminamos datos de la pila? Bueno, como dijimos antes, la pila sigue el principio LIFO, así que en este caso, los últimos datos insertados dentro de la pila serían los primeros en salir de ella. En este caso, hemos puesto "13" como última entrada, así que sería "13" la que eliminaríamos de la pila (como ha sido el último valor que insertamos, es el primer valor que se elimina). Eso es LIFO).
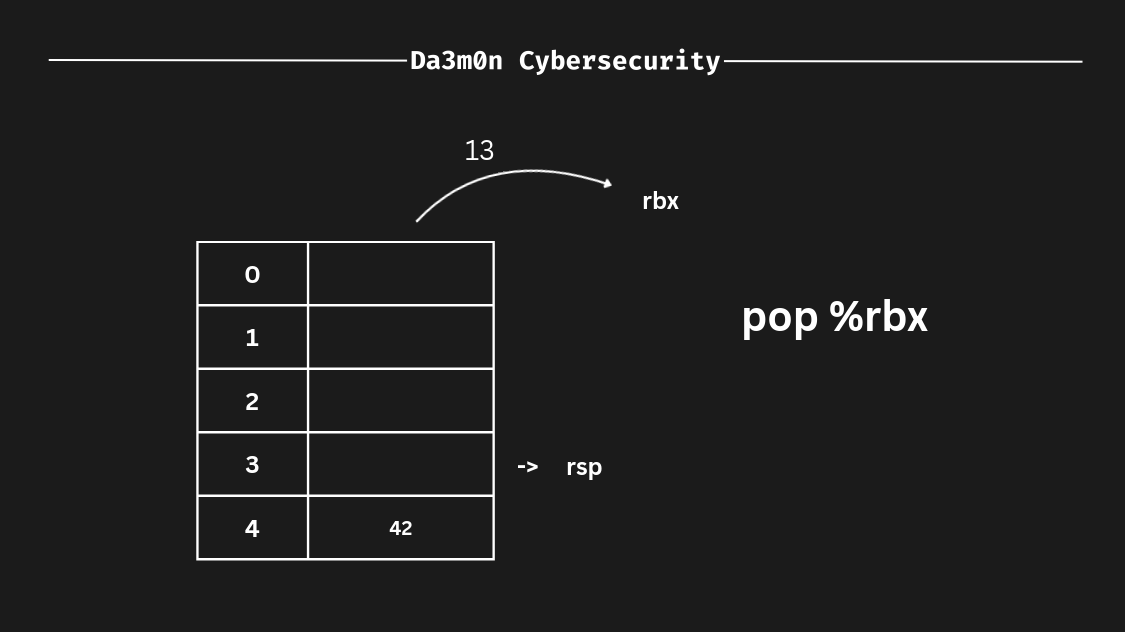
En este caso, siguiendo el principio LIFO (quiero que esto quede más que aclarado), si eliminamos algún valor de la pila (esto se puede hacer usando la instrucción "pop"), funciona de la siguiente manera. Primero, el registro que sigue a la instrucción pop define dónde guardaremos el valor. Luego, el valor "rsp" (puntero de pila, que significa "la parte superior de la pila") se asigna al registro que hemos especificado en la instrucción "pop", y después, el "rsp" permanece vacío, como se mostró antes. Después de que termine la operación, como hemos puesto la dirección 3 en la pila, ahora el "rsp" sería 4 en lugar de 3 (una dirección por debajo del puntero anterior de la pila, "rsp").

Instrucciones
En ASM (Ensamblador), las instrucciones son el equivalente a las acciones que el programa puede realizar para lograr un determinado resultado. Por ejemplo, un conjunto de instrucciones podría calcular el cuadrado de un número específico y guardarlo dentro de la pila. Anteriormente hemos visto 3 instrucciones llamadas "mov", "push" y "pop", pero en ASM hay muchas otras a tener en cuenta, aunque en esta parte de la lección profundizaremos en algunas instrucciones que considero esenciales de entender.
mov
La instrucción "mov", esencialmente, copia el valor desde la fuente hasta el destino. Para ponerlo en perspectiva, si tenemos "50" como fuente y "rax" como destino (verás que "rax" se usa muy a menudo), ahora "rax" almacenaría el valor "50". Si asignamos de nuevo "rax" a "rbx" usando una instrucción mov, ahora "rax" así como "rbx" tendrían el valor "50".

Además, "mov" puede usarse para muchas otras operaciones, como copiar valores no solo de registros sino también de direcciones de memoria usando punteros.
lea
La instrucción "lea" me costó un poco entenderla, pero es bastante sencilla (solo si conoces los punteros y la memoria). "lea" puede verse similar a "mov", porque la sintaxis es realmente parecida. Sin embargo, es un mundo completamente distinto. La instrucción "lea" solo calcula la dirección de memoria a la que se asignaría un valor. Para ponerlo en perspectiva, imagina que tenemos las siguientes instrucciones:
mov $20, %rax
lea (%rax), %rbxEn este caso, especificamos que queremos calcular la dirección de "rax" y almacenarla dentro de "rbx". En este caso, sería equivalente a hacer esto:
mov $20, %rax
mov %rax, %rbxDado que, como almacenamos la posición de "rax" dentro de "rbx", y "rax" almacena el número "20" dentro del registro, "rbx" es por lo tanto equivalente a "20". Explicado de forma más gráfica, esto es de lo que hablo:

Como "rbx" almacenaría la dirección calculada solo para "rax" (por lo tanto, no hay nada que calcular porque especifico que quiero operar solo con "rax"), "rbx" sería igual al valor que contiene "rax". Sin embargo, este no es el caso de uso de la instrucción "lea". De hecho, esta instrucción es muy común en las CPUs actuales porque permite operaciones aritméticas. El uso real de "lea" sería algo así:
lea desplazamiento(origen, índice, escala), destino
desplazamiento -> [Opcional] Espacios en memoria que se va a mover el registro (ha de ser 0 o un número positivo/negativo)
origen -> El registro origen para operaciones aitméticas (%rax, %rbx...)
índice -> [Opcional] Registro para multiplicar por la escala
escala -> Multiplicador que se le aplica al índice
destino -> Registro donde se almacenará la direcciónEsta sería una instrucción "lea" realista:
lea 8(%rax), %rbxEsto obtiene la dirección de memoria "%rax" y luego mueve %rbx los tiempos especificados en el desplazamiento (en este caso, 8). Para representar mejor este ejemplo, echemos un vistazo aquí. Imagina que tengo esta dirección de memoria:
0x0000000000000001
(Esto puede ser interpretado como "0x1")Entonces, si 0x1 es la dirección de "rax". Si ejecutáramos la instrucción "lea" que hemos visto antes, "rbx" almacenaría esta dirección de memoria:
0x0000000000000009
(This can also be interpreted as "0x9")Porque hemos desplazado la dirección de memoria 8 espacios. Pero una operación más compleja sería algo así:
lea 10(%rax, %rcx, 2), %rbxadd
La instrucción "add" suma el valor de la fuente al destino. En este ejemplo, si tengo "50" y quiero sumar 50 a "rax" (que almacena el valor 20), entonces la operación sería:
add $50, %raxLo que haría a "rax" almacenar el valor "70"

sub
El nombre "sub" proviene de "subtract" (significa "sustraer" en español), que es exactamente lo que hace esta instrucción. Es lo opuesto a la instrucción "add". Resta la fuente del destino, como se muestra a continuación.
sub $5, %rax
movl, movq, movb
La instrucción "movl" se utiliza únicamente en la sintaxis de AT&T. En Intel la sintaxis puede verse así:
mov DWORD PTR [...], ...¿Por qué usamos instrucciones diferentes para la misma operación? Porque esto no es realmente una instrucción por sí sola, es una pseudo-instrucción, usada para realizar las mismas operaciones que la instrucción "mov" (por eso en la sintaxis Intel esto no existe), pero moviendo valores grandes. De todos modos, "movl" (que significa "move long" (mover largo), siendo un número "largo" de 32 bits) se usa solo para mover datos de 32 bits (4 bytes) entre registros de 32 bits. Puede que te preguntes: "¿Por qué solo entre registros de 32 bits?". Es porque operamos con 32 bits. Pongámoslo en perspectiva:
movl $12, %raxAquí ponemos todos los bits dentro de los registros (los 32 bits completos porque usamos la arquitectura x86 que funciona con 32 bits) a 0 y escribimos 12 en el registro.
- Nota: Si solo queremos mover 2 bytes (16 bits), pondríamos el "movw", que significa "move word" ("mover palabra" en español).
- AT&T
movw $12, %rax- Intel
mov WORD PTR [...], ...Si quisiéramos operar con los registros completos de 64 bits, usaríamos "movq", que significa "move quadruple word" ("mover palabra quádruple" en español)". En Intel la sintaxis puede verse así:
mov QWORD PTR [...], ...This is used to write to 0 the whole 64-bits (8 bytes) data inside the x86_64 register (for example, "%rax" or "%rbx"). Following the example above, using "movq" for an AT&T instruction would look like this:
movq $12, %raxLater on we'll discuss more complex instructions often used in x86_64 architectures programs.
xchg
La instrucción "xchg" se utiliza para cambiar los registros de valores. Es así de simple. Por ejemplo, podríamos usar la instrucción "xchg" para cambiar los datos dentro de "rax" y "rbx" así.
xchg %rax, %rbx
La memoria
Cuando se habla de ensamblador, la memoria no solo es uno de los elementos más importantes, sino también una parte crucial del lenguaje (y de todo el dispositivo, por supuesto). Ensamblador está fuertemente relacionado con la memoria porque funciona en un nivel tan bajo que necesita especificar direcciones de memoria (algo así como C, pero mucho más específico, ya verás).
La memoria está dividida en lo que se llama "direcciones". Podemos pensar en una dirección de memoria como una región muy pequeña dentro de la memoria que contiene datos. Dependiendo de la arquitectura del sistema, la dirección de memoria puede variar, cambiando así la forma en que el software interactúa con las direcciones de memoria. Hemos visto anteriormente un ejemplo de una dirección de memoria x86_64, sin embargo, para una comprensión adecuada, volveré a poner el ejemplo para refrescarte la mente tras esta cantidad de información.
0x00007FF6B3C42000Y dentro de cada región podemos almacenar una cierta cantidad de datos. Dependiendo del depurador ("debugger" en inglés, herramienta usada para resolución de errores en programación e ingeniería inversa en ciberseguridad), la misma dirección de memoria puede mostrar (no contener, es solo el formato de la aplicación que muestra la información de esa manera) cantidades completamente diferentes por dirección, como hemos hablado. Además, la información se interpreta en hexadecimal para entender mejor lo que contiene la dirección (ya que recordemos que los datos que se guardan están en binario, es sólo que el depurador los expresa en hexadecimal para hacerlo más legible).
Para este ejemplo dejaré aquí un script que escribe la cadena "Da3m0n" directamente en tu memoria dentro de un búfer de 32 bytes (tanto para sistemas Linux como Windows) para que puedas ver cómo se almacena.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
void* pMemoryAdddress = malloc(32);
printf("[+] Base memory address: %p\n", pMemoryAdddress);
char string[8] = "Da3m0n";
memcpy(pMemoryAdddress, string, sizeof(string));
printf("[+] String '%s' copied to the base memory address\n\n", string);
free(pMemoryAdddress);
printf("Press any key to exit...\n");
getchar();
return 0;
}Puedes compilar el código usando "GCC" (GNU C Compiler, "Compilador de C de GNU") con el siguiente comando:
gcc allocate_memory.c -o allocate_memoryCada vez que el código se compila y se ejecuta el binario, se muestra la dirección de memoria donde se encuentra la cadena "Da3m0n", de la siguiente manera:
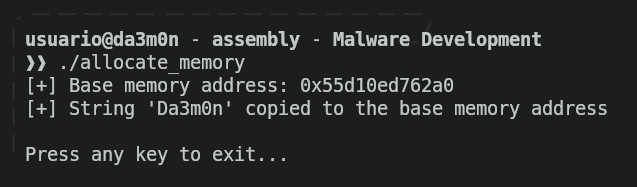
El programa terminará su ejecución una vez que se pulse una tecla. Si queremos verificar que la cadena se ha almacenado dentro de esa dirección de memoria, podemos usar "GDB" (GNU Debugger, "Depurador de GNU" en español), que servirá como herramienta para comprobar la ejecución del programa y comprobar si está donde se supone que debe. Para ello, solo ejecutaremos el siguiente comando y entraremos en la consola:
gdb allocate_memory
Ahora que estamos dentro de la consola GDB, podemos usar diferentes comandos para comenzar la depuración. Primero tenemos que tener en cuenta que el script borra la cadena que hemos puesto en la memoria (porque hemos usado la función "free") poco antes de que nos diga que pulsemos cualquier tecla. Por lo tanto, si queremos ver realmente el valor que hay dentro de la dirección de memoria, tendremos que detener la ejecución del programa antes de que ocurra. Para eso, usaremos el comando "break" (que proviene de "breakpoint") que nos permitirá detener la ejecución en una determinada instrucción de ensamblador.
Para especificar un punto de interrupción necesitaremos la dirección de memoria donde está la instrucción (para indicar a GDB que detenga la ejecución una vez que el flujo de ejecución llegue a ese punto). Para eso, usaremos el comando "disas main".
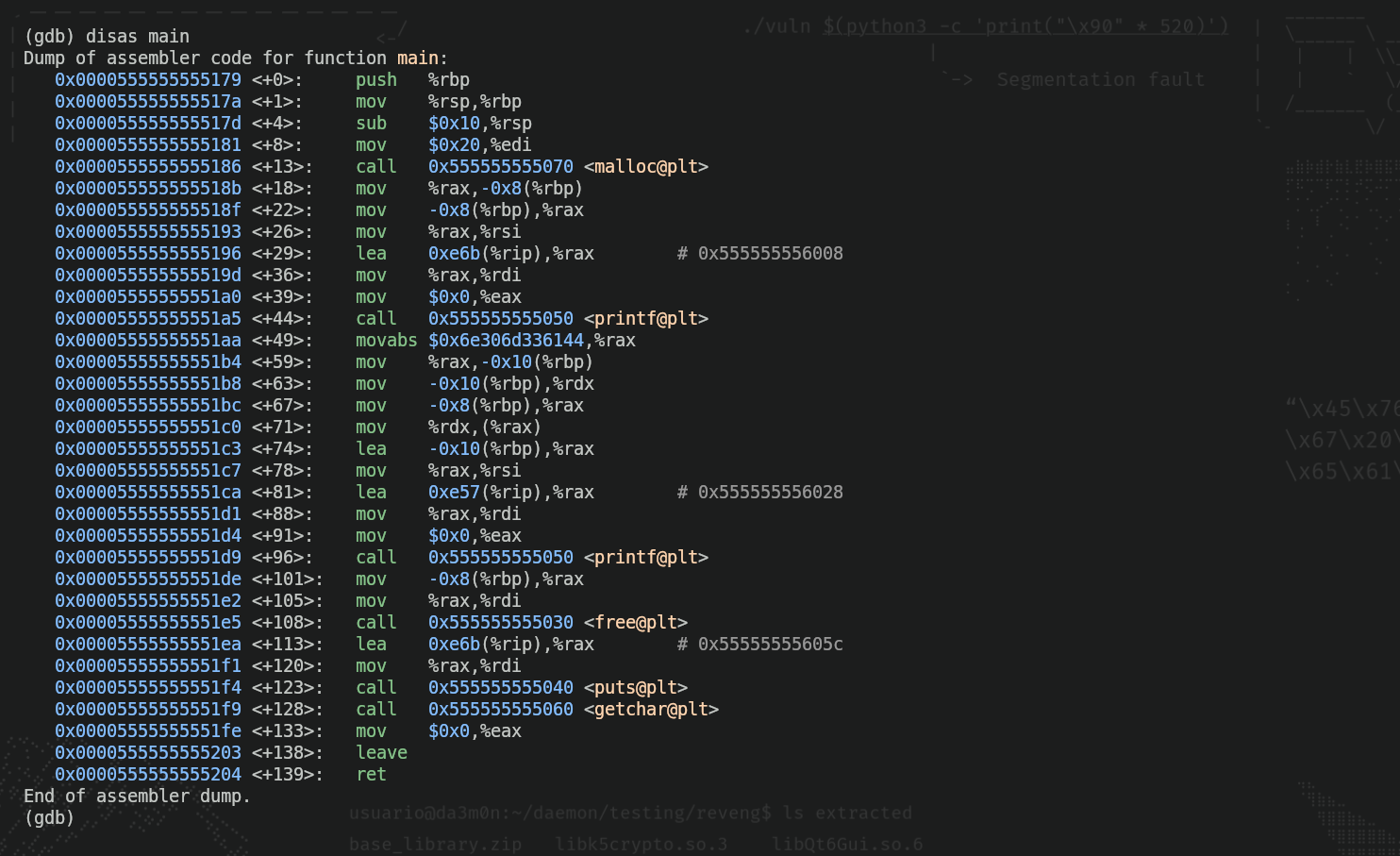
Como podemos ver, dentro de todas esas instrucciones (no te preocupes si no las entiendes todas, por ahora está bien) hay una instrucción que contiene la palabra "free" (free@plt). Esa es la parte en la que el programa borra la memoria que hemos asignado para esa cadena, así que antes de esa instrucción pondremos un punto de interrupción (el "*" se usa para indicar a GDB que asignaremos un punto de interrupción, un "breakpoint", a una dirección de memoria).
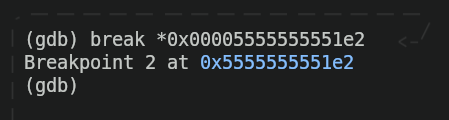
Ahora ejecutaremos el programa y comprobaremos que, efectivamente, el programa se detenga justo antes de poner el mensaje "Pulse cualquier tecla para salir..."
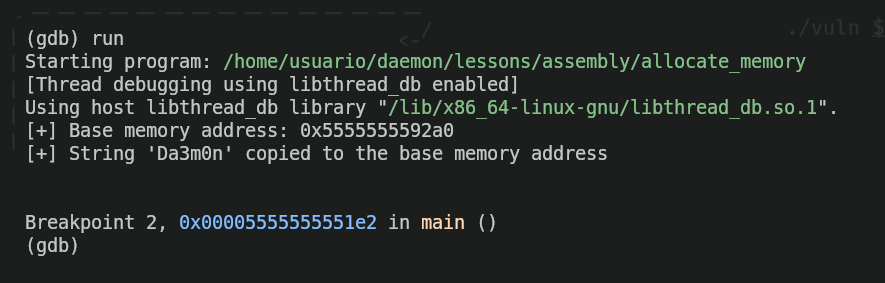
Ahora, comprobaremos si la cadena "Da3m0n" está realmente dentro de la dirección de memoria "0x5555555592a0", como dice el programa. Para eso, usaremos el siguiente comando:
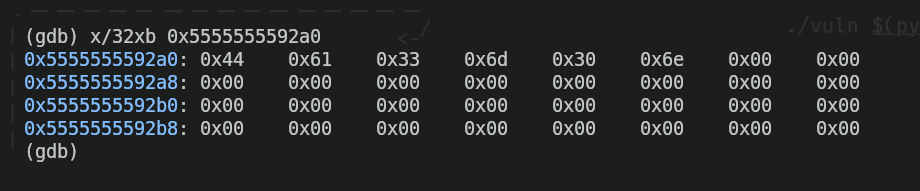
Podemos ver que tenemos un conjunto de valores hexadecimales dentro de la dirección, junto con muchos ceros. Voy a explicar primero por qué esto es lo que esperábamos y por qué tiene sentido:
xen GDB es una abreviatura de "examine". El comando "examine" se usa, efectivamente, para examinar lo que hay dentro de la memoria./es el separador que indica que queremos especificar algunos filtros y formatos al examinar la memoria, y el "32xb" que sigue son el filtro y los formatos.32significa que queremos filtrar (mostrar) los 32 bytes de memoria (1 byte equivale a "0xFF" en hexadecimal) que vienen después de la dirección de memoria especificada.xbsignifica que quiero formatear la información de memoria en hexadecimal (la "x") y los datos dentro de la dirección de memoria deben estar formateados en bytes (la "b"). Por eso existe una separación entre cada byte.
También podemos ver que tenemos un montón de ceros. Esto se debe a que, al escribir el programa, especifiqué la cantidad de bytes que quería reservar en memoria (en este caso especificé 32, y si cuentas cada byte en la salida mostrada arriba, efectivamente hay 32 bytes), y hay algunos bytes de esos 32 (los que aparecen al principio de la dirección) que están llenos con valores hexadecimales. Cada uno de esos valores es una letra de la cadena que especifiqué dentro del código ("Da3m0n"), así que la "D" en hexadecimal sería "0x44", la "a" sería "0x61", y así sucesivamente. Para comprobar que esto es real y que no miento, podemos usar el comando xxd para ver la traducción literal de esos valores hexadecimales.

Y como hemos visto, hemos revisado con éxito la ejecución del comando y verificado que funciona correctamente.
Referencias